

{kind=link}
Links are our bread and butter: We create backlink campaigns, reach out to journalists to get coverage and more visibility for your brand. But as a digital PR and SEO agency, we are also aware of the other bits that matter to get your website where you want it to be. It is no secret that your SEO needs backlinks, but your backlinks need some decent SEO too because if Google’s crawlers cannot read the content on your website, even the best links will not get it ranking. These are some important things to look out for on your website.
Robots.txt
This happens often when a new website is launched. During the development phase of the site, there are usually many flaws. At that stage it is a good idea to “hide” the website from Google until it is ready to be shared with the world. You could compare it to the “closed for refurbishment” sign in a shop window. There are two common ways to put up that sign on your website: you can either protect the website with a password or alternatively add a disallow directive in robots.txt for search engine crawlers. This is what it looks like:
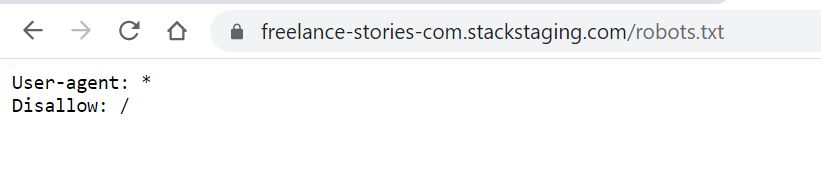
That is not a lot of code, but it can do a lot of damage. The above robots.txt file will indicate to any crawler, not just Google’s, that this whole website should not be crawled. The crawler is not allowed to go there. In the above case, that is intended because that website is under development, it is a staging site.
A few weeks might pass, the website takes shape and everybody who is involved in the process is getting excited. Launch day! The website is pushed live and the whole world can see it – the whole world but Google. With all that excitement, you forgot to remove the disallow line in the robots.txt file and your beautiful new website is still hidden. It is as if you opened the doors to your shop, but the window still shows “closed for refurbishment”.
If that has happened, you should remove the disallow line in your robots.txt file as soon as possible and we would also recommend submitting your homepage URL and XML-sitemap in Google Search Console. Google can now see your website and your backlinks!
No-index tags
This is a different technical setup and circumstance, but the impact can be the same as the disallow directive in the robots.txt file. The difference though is that this piece of code is added to individual pages rather than the whole website and Google is still able to crawl the content but is told to not index it. The result is the same: This content will not appear in Google search.
This is how it looks in the html code:

We imagine the following scenario:
Mary wants to publish content about travelling to cities in Italy. There are already similar pages for Spain on the website with URLs like that: /spain/madrid/, /spain/seville/ etc. For Italy, Mary has ordered and received content for pages about Rome and Florence. She wants to publish it with the following URLs /italy/rome/ and /italy/florence/. That is when she notices that she does not have content to fill the page about Italy with. She asks her manager John for additional budget to order content about Italy. John tells her that there is no content budget left for this month, but that she would be able to order it next month. Mary though does not want to delay the publication of the content about Rome and Florence. She decides to publish a placeholder page /italy/ in order to get the URL structure she wants. That placeholder page will be empty until she receives the content – next month. Because she does not want Google to waste any crawl budget on an empty page, she adds a no-index tag to the page.
A month later, Mary finally receives the content for the general page about Italy. She adds it to the page which is now no longer empty. She is proud of that content with beautiful images from all corners of Italy. Because she knows about SEO and wants Google to index that content, she removes the no-index tag and submits the page in Google Search Console. Mary has done a good job, but you can see how easily she could have forgotten that seemingly small technicality, especially when she dreams of a trip to Italy.

Lake Como. Photo by Mariya Georgieva on Unsplash
Crawl budget
Mary has taken crawl budget into account and that is important, especially if you have quite a big website. Even Google has a budget when it comes to crawling resources, it is a big effort to keep its index up to date. The budget that Google allocates to your website should be used for the pages that matter, instead of crawling empty pages. Another way to waste crawl budget is to redirect crawlers many times. If a URL redirects once, that is not an issue, but if it redirects multiple times or if every single internal link on your site redirects, that could become a problem. At some point, the crawlers will stop following your links. That is something to keep an eye on. (Besides, redirects also have a negative impact on your page load times – another SEO ranking factor.)
If you want to use your crawl budget wisely, you can do that by ensuring a good internal linking strategy and site architecture. Every page on your website should be linked to internally and the pages that hold most value should receive the highest number of internal links.
Getting your technical SEO right
This was just a glimpse of the things that could go wrong when it comes to technical SEO, but it should have given you a good overview of its impact. If you reach out to an agency like JBH for link building, it is important to look at the overall health of your website. And if you are already engaged in digital PR, you get media coverage, but your rankings are not improving, it is time to audit your whole website. It could be a small technical detail that prevents Google from seeing all the work you do.